12th November 2020 New algorithm provides 50 times faster deep learning Using algorithms derived from neuroscience, AI research company Numenta has achieved a dramatic performance improvement in deep learning networks, without any loss in accuracy. Their breakthrough is also vastly more energy efficient.
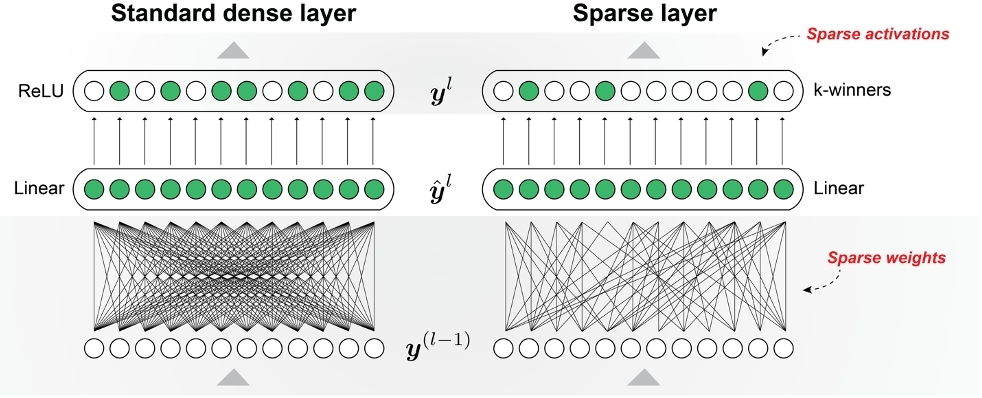
Today's deep learning networks have accomplished a great deal but are running into fundamental limitations – including their need for enormous compute power. A large, complex model can cost millions of dollars to train and to run, and the power required is growing at an exponential rate. New algorithms are essential to break through this performance bottleneck. California-based Numenta this week announced a major breakthrough, based on a principle of the brain called sparsity. Researchers at the company developed a new algorithm by comparing "sparse" and "dense" networks (illustrated above) for a speech recognition task, using the Google Speech Commands (GSC) dataset. The team ran their programs through field-programmable gate arrays (FPGAs), a type of integrated circuit designed to be configured by a customer or designer after manufacturing, supplied by Xilinx. Based on the metric of words processed per second, the sparse networks yielded more than 50 times the acceleration over dense networks on a Xilinx Alveo circuit board. In addition, Numenta demonstrated their network running on a Xilinx Zynq – a smaller chip where dense networks are too large to run – enabling a new set of applications that rely on low-cost, low-power solutions. As a result, when measured by words per second per watt, Numenta has shown a 2600% saving in energy efficiency. This proof-of-concept demonstration validates that sparsity can achieve substantial acceleration and power efficiencies for a variety of deep learning platforms and network configurations, while maintaining competitive accuracy. It provides an exponential improvement in terms of larger and more complex networks using the same resources.
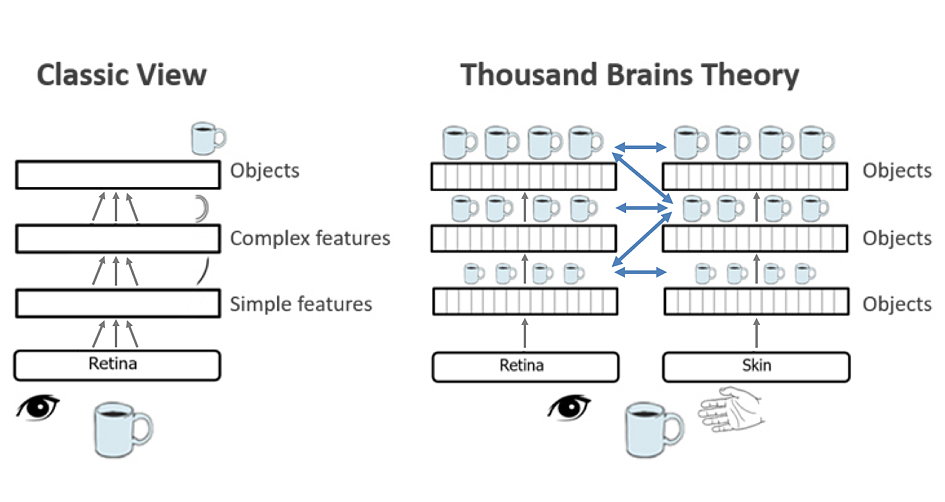
"New algorithmic-hardware approaches are required to advance machine intelligence," explains Priyadarshini Panda, Assistant Professor at Yale University in Electrical Engineering. "The brain offers the best guide for achieving these advances in the future. The results announced by Numenta demonstrate great promise by applying its cortical theory to achieve significant performance improvements." In recent years, the team at Numenta has put forward a novel idea to explain the workings of the neocortex – a six-layered and dominant brain region involved in higher-order functions such as sensory perception, cognition, motor commands, spatial reasoning and language. A new book, to be published in March 2021, explores their concept in more detail. The Thousand Brains Theory of Intelligence proposes that, rather than learning one big model of an object or concept, the brain creates many different models of each object. Each model is built using different inputs, whether from slightly different parts of a sensor (such as different fingers on your hand), or from different sensors altogether (eyes vs. skin). The models "vote" together to reach a consensus on what they are sensing, and the consensus vote is what we perceive. In other words, it is almost like your brain is actually thousands of brains working simultaneously and in parallel. This is shown in the diagram below with complete models of objects already existing at each level of hierarchy for the cortex, which can be enhanced by long-range connections between columns. A paper from Numenta ranked as one of the most downloaded on BioRxiv in 2018. Numenta applied this theory to develop their new sparsity-based algorithm. "Sparsity is foundational to how the brain works and offers the key to unlocking tremendous performance improvements in machine learning today," said Subutai Ahmad, Numenta's VP of Research and Engineering. "Going forward, Numenta's neuroscience research has generated a roadmap for building machine intelligence which will yield equally exciting improvements in robustness, continual learning, unsupervised learning and sensorimotor integration." "We now see a clear roadmap to apply these concepts to building efficient, intelligent machines," the team explains in a white paper. "We propose a starting point of using sparsity to dramatically improve the performance of deep learning networks. As we continue to implement more and more of the Thousand Brains Theory in algorithms, we are confident that we are finally on the path to machine intelligence."
--- Follow us: Twitter | Facebook | Instagram | YouTube
Comments »
If you enjoyed this article, please consider sharing it:
|