10th July 2025 Grok 4 brings ARC-AGI breakthrough closer xAI's new model, Grok 4, has reached a major milestone in reasoning tasks, doubling the previous record on a key metric. Rapid gains suggest artificial general intelligence (AGI) could be closer than many thought.
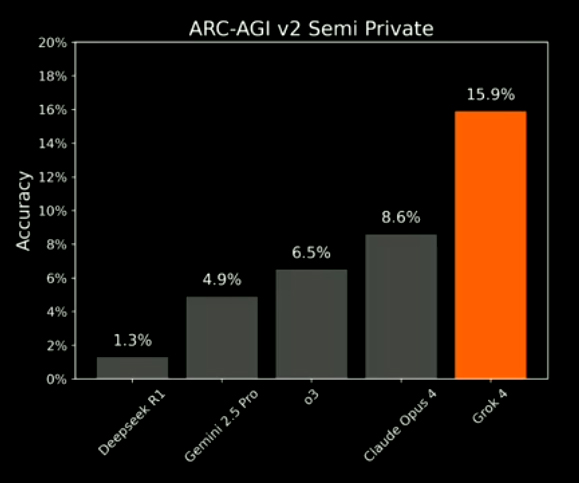
Like him or loathe him, Elon Musk has once again made headlines – this time for pushing the boundaries of artificial intelligence (AI). His company, xAI, has just announced the release of Grok 4, the latest and most powerful version of its chatbot. Grok 4 has surprised many with its capabilities, delivering a significant leap above previous models. This new version is particularly impressive when it comes to advanced reasoning and generalisation. Like its predecessor, it also features multimodal capabilities, combining text, images, and code. Available to X Premium and X Premium+ subscribers, Grok 4 continues Musk's effort to rival OpenAI, Anthropic, and Google in the race for next-generation AI. Founded in March 2023, xAI began with relatively modest offerings. Early versions of Grok focused on humour-infused answers and integration with X's data. However, the pace of progress has been astonishing. In just two years, the company has established the largest AI training platform in the world – an in-house compute cluster known as Colossus, or the Gigafactory of Compute, located in Memphis, Tennessee. The facility reached 100,000 Nvidia GPUs in just 122 days, then doubled to 200,000 only 92 days later – making it the most powerful AI supercomputer currently in operation. xAI now plans to scale this further into a million-GPU supercluster, with backing from partners including Nvidia, Dell, and Supermicro. Supported by a gigantic infrastructure and set to grow even larger, xAI describes Grok 4 as "the world's most powerful AI model." That claim isn't just marketing hype. Grok 4 has achieved 15.9% accuracy on the ARC-AGI-2 benchmark – a deceptively difficult set of abstract reasoning tasks designed to test human-like intelligence. While that percentage may seem modest at first glance, it marks a major leap forward – nearly doubling the previous best of 8.6%, set by Anthropic's Claude Opus 4 just weeks earlier. In a field where most models struggle to get beyond a few percent, Grok 4 now stands clearly ahead of every other known AI system.
What is ARC-AGI-2? The Abstraction and Reasoning Corpus for AGI (ARC-AGI) is a benchmark created by François Chollet, a French software engineer and AI researcher who also developed the Keras deep-learning library. Unlike most benchmarks that reward pattern-matching on large datasets, ARC-AGI tests for cognitive flexibility, symbolic reasoning, and generalisation to novel problems – traits we typically associate with human intelligence. Version 2 of ARC-AGI, launched in March 2025, represents the second generation of this challenge. Each task involves a small grid of coloured shapes, with a few examples of input–output pairs. The AI must figure out the hidden rule and apply it to a new test case. No external data, brute-force trial-and-error, or pretraining on similar examples is allowed. To pass a challenge – one example of which is shown below – a model must generate the correct output on all test cases within a problem. Humans can solve nearly all of them with ease. For machines, however, they represent a formidable hurdle on the path to AGI.
ARC-AGI-2 contains 360 evaluation tasks, divided into three groups: • Public Evaluation – released for testing and experimentation • Semi-Private Evaluation – used for leaderboard rankings • Private Evaluation – hidden, reserved for final judging In addition to these, a separate Public Training Set of 1,000 tasks is available for model development, but is not used in scoring or competition rankings. Grok 4's score of 15.9% reflects its performance on the Semi-Private set, making it the top model on the current ARC Prize leaderboard. While this result may seem low, it represents a notable leap. Just four months ago, the best models were scoring under 2%. Since then, OpenAI's o3, Anthropic's Claude Opus 4, and others have made gains – but Grok 4's leap is by far the most dramatic, and the first to reach a double-digit percentage. Beyond ARC-AGI-2, Grok 4 also topped several other advanced reasoning benchmarks. It scored 25.4% on "Humanity's Last Exam" – a 2,500-question test designed to evaluate post-graduate-level knowledge across dozens of subjects. With external tool use, it reached 38.6%, while the "Heavy" version of Grok 4 climbed above 44%. On the American Invitational Mathematics Examination (AIME), Grok 4 achieved a perfect 100%, compared to Grok 3's 52.2%. If the current rate of progress continues, we may actually see the first model reach 100% accuracy on both Humanity's Last Exam and ARC-AGI-2 before the end of this year. That would be a groundbreaking moment: a clear signal that AI is beginning to rival human abilities, not just in advanced academic knowledge but in certain aspects of abstract reasoning.
Comments »
If you enjoyed this article, please consider sharing it:
|