16th April 2021 New processor will enable 10 times faster training of AI NVIDIA has unveiled "Grace" – its first data centre CPU, which will deliver a 10x performance leap for systems training AI models, using energy-efficient ARM cores. The company also revealed plans for a 20 exaflop supercomputer.
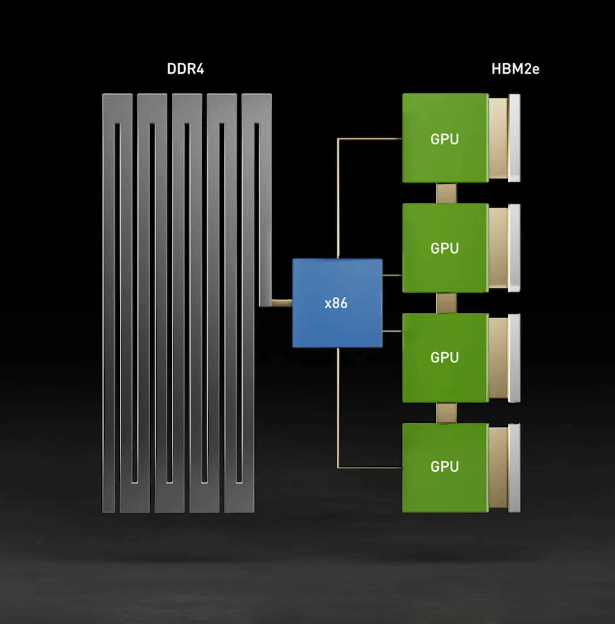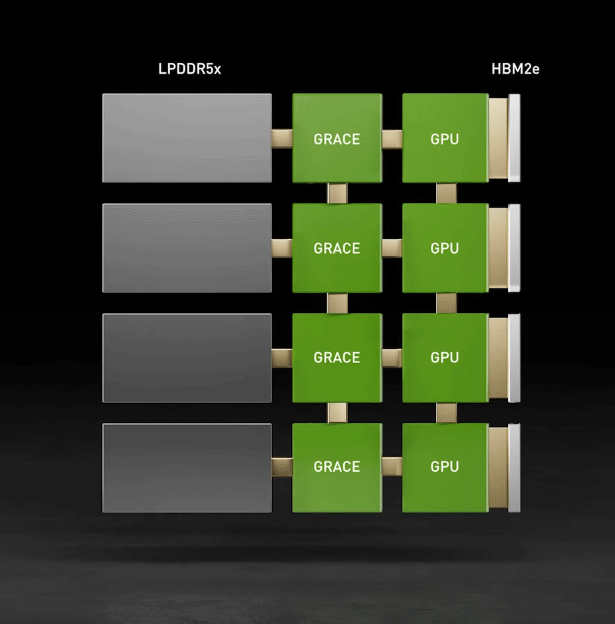
The GPU Technology Conference (GTC) has been taking place this week, with technology company NVIDIA revealing its latest products, which include advancements in 5G, AI, automotive, data centres, real-time graphics, and robotics. A major highlight of this virtual conference is "Grace" – a next-generation, ARM-based central processing unit (CPU) designed specifically for giant-scale AI and high-performance computing (HPC) applications. The processor is named after Grace Murray Hopper, a computer scientist who pioneered programming languages in the 1950s. Current x86 server architectures provide flexibility and varying configurations of CPU, memory, PCI Express and peripherals. Nevertheless, processing large amounts of data remains a major challenge for today's systems. This is particularly true when it comes to artificial intelligence (AI) models, such as deep learning and neural networks. An example of this bottleneck is shown in the animation below. In the older x86 system, each graphical processing unit (GPU) is starved by the CPU memory and PCIE bandwidth. One possible configuration might be to quadruple the links between the DDR4 memory and GPUs, with a dedicated channel to feed each GPU. However, PCI Express would remain as a bottleneck. The volume of data and size of AI models are growing exponentially. Today's largest AI models include many billions of parameters and are doubling every two and a half months. Training them requires a new CPU that can be tightly coupled with a GPU to eliminate system bottlenecks. To overcome these issues, NVIDIA is developing Grace, its first ever data centre CPU. This will be purpose-built for accelerated computing applications with large amounts of data, such as AI. Since it is ARM-based, rather than x86-based, NVIDIA has been able to design Grace to be the optimal CPU. It will feature ARM's next-generation "Neoverse" CPU cores, as well as LPDDR5x memory subsystems. In addition, "unified cache coherence" with a single memory address space – combining system and high-bandwidth GPU memory – will simplify programmability.
The new architecture will enable huge improvements in data throughput. When coupled with NVIDIA GPUs, a Grace CPU-based system will deliver 10 times faster performance than today's state-of-the-art NVIDIA DGX-based systems, which run on x86 CPUs. Grace will create a third foundational technology for computing and the ability to rearchitect every aspect of data centres for AI. "Leading-edge AI and data science are pushing today's computer architecture beyond its limits – processing unthinkable amounts of data," said Jensen Huang, founder and CEO of NVIDIA. "Using licensed ARM IP, NVIDIA has designed Grace as a CPU specifically for giant-scale AI and HPC. Coupled with the GPU and DPU, Grace gives us a third foundational technology for computing, and the ability to re-architect the data centre to advance AI. NVIDIA is now a three-chip company." "As the world's most widely licensed processor architecture, ARM drives innovation in incredible new ways every day," said Simon Segars, the CEO of ARM. "NVIDIA's introduction of the Grace data centre CPU illustrates clearly how ARM's licensing model enables an important invention, one that will further support the incredible work of AI researchers and scientists everywhere." Availability is expected in 2023. That same year, a 20 exaflop AI supercomputer based on the Grace CPU is planned by the Swiss Supercomputing Centre in collaboration with the US Department of Energy's Los Alamos National Laboratory. Known as "ALPS", this will be deployed for climate and weather simulations along with research into astrophysics, molecular dynamics, quantum physics for the Large Hadron Collider, and much more. ALPS will also train GPT-3, one of the world's largest natural language processing models, in only two days. That is nearly an order of magnitude faster than NVIDIA's Selene, currently recognised as the world's leading AI-specialised supercomputer. Larger AI model sizes will also become possible. While GPT-3's full version has a capacity of 175 billion machine learning parameters, Huang said during a keynote presentation that he expects to see multi-trillion parameter models next year and 100 trillion+ parameter models in 2023. As a loose comparison, the human brain has roughly 125 trillion synapses. "Today's monumental scientific challenges demand a new kind of supercomputer to fuel discovery," said Huang. "Taking advantage of our new Grace CPU designed for giant-scale AI and HPC, CSCS and NVIDIA are joining together to blaze a new trail – building a world-class, ARM-based supercomputing infrastructure that will let leading scientists apply the power of AI to do world-changing research."
Comments »
If you enjoyed this article, please consider sharing it:
|