17th February 2026 NVIDIA claims 50x AI performance leap with Blackwell Ultra New benchmark data indicate that NVIDIA's latest AI platform delivers up to 50 times greater inference efficiency than the previous generation. Large-scale deployment is expected through 2026 and 2027.
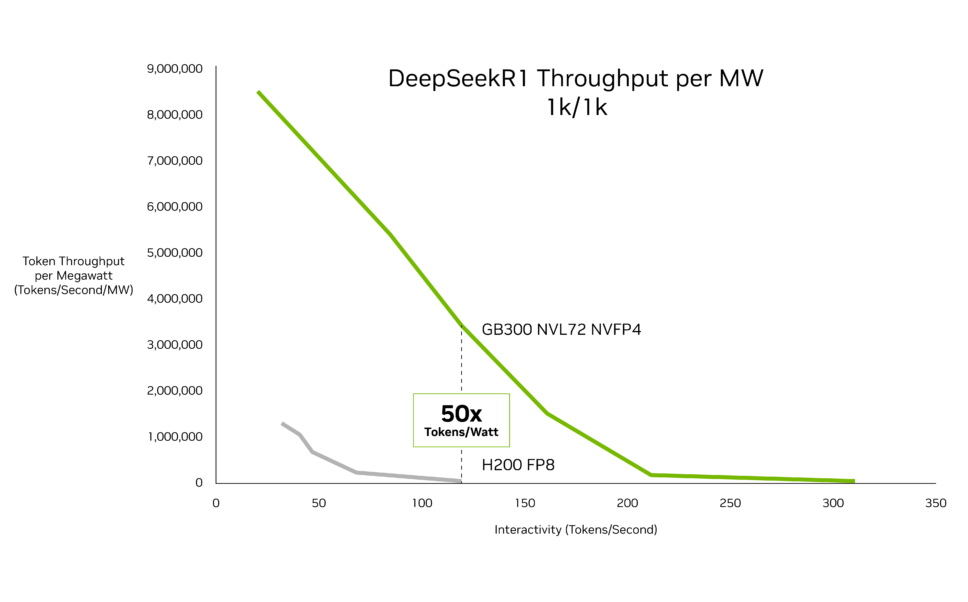
The global race to build ever more powerful artificial intelligence systems has accelerated dramatically over the past few years. Model sizes have ballooned from billions to trillions of parameters, inference workloads have expanded to run at vast scale across global cloud platforms, and companies are racing to deploy increasingly capable "agentic" systems that can reason, plan, and act autonomously. At the same time, concerns about rising energy consumption, supply chains and resource use have grown. Training and running large AI models requires huge data centres packed with high-end accelerators such as graphics processing units (GPUs), drawing many megawatts of power and driving demand for advanced chip packaging, high-bandwidth memory, and cutting-edge fabrication nodes. A study published in December found that the carbon footprint of today's AI is comparable to that of a major city such as New York, while its water footprint may be on a scale approaching global annual bottled water consumption. In this context, performance per watt is becoming as critical as raw speed. The economic viability of next-generation AI now depends not only on how fast a chip can run, but on how efficiently it can process and generate tokens – the units of text that language models use – at scale. Against this backdrop, NVIDIA has released new performance data for its latest Blackwell Ultra platform, claiming up to 50 times higher performance per watt during AI inference – the stage at which trained models generate responses – compared with previous-generation systems in agentic workloads. The figures, published this week and based on independent benchmarking by research company SemiAnalysis, focus mainly on throughput per megawatt and cost per token rather than headline floating-point performance.
NVIDIA's "Hopper" architecture, including chips such as the H100 and H200, has powered much of the recent AI boom. The "Blackwell" family, launched in 2024, represented a major architectural shift, with improved tensor cores, higher memory bandwidth, and a multi-die design that enabled bigger, more efficient GPUs. An even more powerful version, Blackwell Ultra, has since built on this foundation, combining upgraded GPUs into high-density rack-scale systems such as the GB300 NVL72 and tightly integrating dozens of accelerators using high-speed interconnects. In the workloads highlighted by NVIDIA – particularly those involving large-scale inference for coding assistants and autonomous AI agents – the newer systems reportedly achieve up to 50 times more tokens per megawatt compared with the Hopper platform. The company also cites up to 35 times lower cost per token in those same scenarios. These gains reflect architectural improvements, software stack optimisation and system-level design rather than a single breakthrough in transistor performance. Mass production of the original Blackwell-based systems began in December 2024, with first shipments in January 2025. Early deployments of Blackwell Ultra began in late 2025, with broader rollouts and cloud-scale clusters coming online in early 2026. Wider adoption across hyperscale data centres is likely to continue into 2027, as providers integrate the newer hardware into existing AI infrastructure. As these efficiency gains move from benchmarks and into large-scale deployment, several new capabilities become more economically viable. More powerful agentic AI systems, capable of sustained reasoning over longer contexts and operating continuously in the background, can be deployed without proportionally increasing energy use. Enterprises may run advanced language models internally at lower cost, while cloud platforms can offer more sophisticated AI services to a broader customer base. Yet another family of chips, known as "Rubin", has already been announced, with availability set for later this year. NVIDIA expects a further order of magnitude reduction in token costs compared with Blackwell, alongside major reductions in training hardware requirements. This rapid succession of architectures underlines the extraordinary and ongoing pace of progress in AI hardware.
Comments »
If you enjoyed this article, please consider sharing it:
|