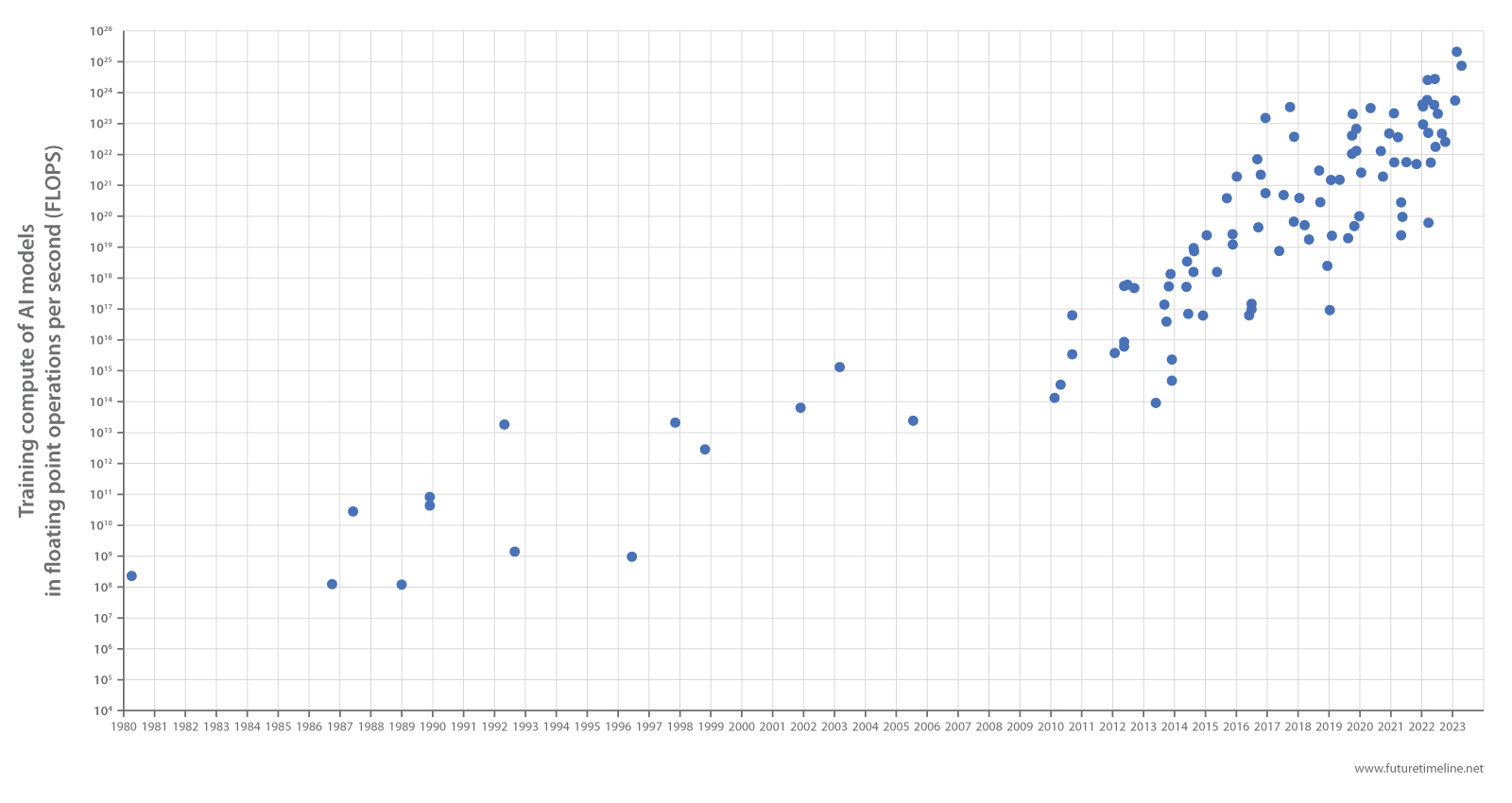
AI training models will be "1,000x larger in three years"
DeepMind co-founder and Inflection CEO Mustafa Suleyman predicts that AI will continue its exponential progress, with orders-of-magnitude growth in model training sizes over the next few years.
Deep learning models began to disrupt the field of artificial intelligence (AI) in the early 2010s. As a subset of machine learning, they offered new capabilities in tasks ranging from image and speech recognition to natural language processing, thanks to algorithms inspired by the structure and function of the brain, specifically neural networks with multiple layers. By contrast, traditional AI has tended to rely on "hard-coded" programs for specific tasks, and lacks the automatic feature-learning capabilities of deep learning.
Transformer architecture, introduced in 2017, set the stage for even more advanced and versatile models. This included Generative Pre-trained Transformer (GPT) and its subsequent versions. GPT-3.5 burst onto the scene in 2022 as the publicly available ChatGPT, and more recently, has been upgraded to 4.0 with still greater capabilities. While the exact model size of GPT-4 remains unknown to the public, numerous other large language models (LLMs) have been released in the early 2020s with parameter counts in the hundreds of billions or more, some featuring multimodality.
Fast-forward to the present day, and we find ourselves at an inflection point. Algorithms have grown exponentially in both size and proficiency. A question that now looms large is: what comes next? In a recent interview with 80,000 Hours, DeepMind co-founder and Inflection CEO Mustafa Suleyman predicted that AI will continue its rapid progress, with additional orders-of-magnitude leaps in model training sizes over the next few years.
This might mean, for example, that an entire bookshelf of text could be entered as a prompt, compared with a maximum of around 50 pages for GPT-4 and just seven pages for GPT-3.5. Multimodal inputs, taken to a whole new level, might perform detailed and complex analyses of video content.
But while AI could accelerate progress in science and technology – finding new treatments for cancer and aging, for example, or creating entire new movies with virtual actors – underlying dangers will accompany LLMs and other models. Like previous, world-altering technologies such as nuclear weapons, misaligned AI in the wrong hands could be an existential threat.
Suleyman co-founded DeepMind in 2010, after a career that included policy work on human rights. At the London-based company, he spearheaded initiatives like DeepMind Health and energy-efficient cooling systems for Google data centres, as well as setting up a research unit called DeepMind Ethics and Society. In 2022, having left both DeepMind and Google, he then co-founded Inflection AI with the goal of leveraging "AI to help humans 'talk' to computers". Inflection has launched a chatbot named Pi, which stands for Personal Intelligence, able to "remember" past conversations and get to know its users over time, offering people emotional support when needed. The company has also built a supercomputer with 22,000 NVIDIA H100 GPUs, one of the largest in the industry.
Suleyman began by talking about his new book, The Coming Wave: Technology, Power, and the Twenty-first Century's Greatest Dilemma, published this week and described as "an urgent warning of the unprecedented risks that AI and other fast-developing technologies pose to global order, and how we might contain them while we have the chance".
The book paints a worrying picture of the decades ahead. However, Suleyman insisted that he is a realist, telling 80,000 Hours' Robert Wiblin: "So people have this fear, particularly in the US, of pessimistic outlooks. I mean, the number of times people come to me like, 'You seem to be quite pessimistic.' No, I just don't think about things in this simplistic 'Are you an optimist or are you a pessimist?' terrible framing. It's BS. I'm neither. I'm just observing the facts as I see them, and I'm doing my best to share for critical public scrutiny what I see. If I'm wrong, rip it apart and let's debate it. But let's not lean into these biases either way."
In The Coming Wave, Mustafa describes 10 steps that the world should urgently take to limit negative and unforeseen consequences of emerging technologies:
• Develop an Apollo programme for technical AI safety
• Institute capability audits for AI models
• Buy time by exploiting hardware choke points
• Get critics involved in directly engineering AI models
• Get AI labs to be guided by motives other than profit
• Radically increase governments' understanding of AI and their capabilities to sensibly regulate it
• Create international treaties to prevent proliferation of the most dangerous AI capabilities
• Build a self-critical culture in AI labs of openly accepting when the status quo isn't working
• Create a mass public movement that understands AI and can demand the necessary controls
• Not rely too much on delay, but instead seek to move into a new somewhat-stable equilibria
The interview touched on how soon these threats may emerge:
Rob Wiblin: OK, so maybe the idea is in the short term, over the next couple of years, we need to worry about misuse: a model with human assistance directed to do bad things, that's an imminent issue. Whereas a model running somewhat out of control and acting more autonomously without human support and against human efforts to control it, that is more something that we might think about in 10 years' time and beyond. That's your guess?
Mustafa Suleyman: That's definitely my take. That is the key distinction between misuse and autonomy. And I think that there are some capabilities which we need to track, because those capabilities increase the likelihood that that 10-year event might be sooner. For example, if models are designed to have the ability to operate autonomously by default: so, as an inherent design requirement, we're engineering the ability to go off and design its own goals, to learn to use arbitrary tools to make decisions completely independently of human oversight. And then the second capability related to that is obviously recursive self-improvement: if models are designed to update their own code, to retrain themselves, and produce fresh weights as a result of new fine-tuning data or new interaction data of any kind from their environment, be it simulated or real world. These are the kinds of capabilities that should give us pause for thought.
Suleyman thinks OpenAI is secretly training GPT-5:
I think Sam [Altman] said recently they're not training GPT-5. Come on. I don't know, I think it's better that we're all just straight about it. That's why we disclose the total amount of compute that we've got. [...] I think Google DeepMind should do the same thing. They should declare how many FLOPS Gemini is trained on.
Click to enlarge
Regarding model open sourcing, Suleyman had this to say:
If we just continue to open source absolutely everything for every new generation of frontier models, then it's quite likely that we're going to see a rapid proliferation of power. These are state-like powers which enable small groups of actors, or maybe even individuals, to have an unprecedented one-to-many impact in the world.
Just as social media has enabled anybody to have broadcast powers, to essentially function as an entire newspaper from the 1990's: by the 2000's, you could have millions of followers on Twitter or Instagram or whatever, and you're really influencing the world – in a way that was previously the preserve of a publisher, that in most cases was licenced and regulated, that was an authority that could be held accountable if it really did something egregious. And all of that has now kind of fallen away. For good reasons, by the way, and in some cases with bad consequences.
We're going to see the same trajectory with respect to access to the ability to influence the world. You can think of it as related to my Modern Turing Test that I proposed around artificial capable AI: like machines that go from being evaluated on the basis of what they say – you know, the imitation test of the original Turing test – to evaluating machines on the basis of what they can do. Can they use APIs? How persuasive are they of other humans? Can they interact with other AIs to get them to do things?
So if everybody gets that power, that starts to look like individuals having the power of organisations or even states. I'm talking about models that are two or three or maybe four orders of magnitude on from where we are. And we're not far away from that. We're going to be training models that are 1,000x larger than they currently are in the next three years. Even at Inflection, with the compute that we have, will be 100x larger than the current frontier models in the next 18 months.
Although I took a lot of heat on the open source thing, I clearly wasn't talking about today's models: I was talking about future generations. And I still think it's right, and I stand by that – because I think that if we don't have that conversation, then we end up basically putting massively chaotic destabilising tools in the hands of absolutely everybody. How you do that in practise, somebody referred to it as like trying to catch rainwater or trying to stop rain by catching it in your hands. Which I think is a very good rebuttal; it's absolutely spot on: of course, this is insanely hard. I'm not saying that it's not difficult. I'm saying that it's the conversation that we have to be having.
His interviewer, Rob Wiblin, agreed:
Interesting. Yeah. I'm concerned about having this precedent where people just say we have to open source everything. Then where does that leave us in five years or 10 years or 15 years or 20 years? They're going to just keep getting more powerful. And currently it's not really any help with designing a bioweapon, but in 10 years' time or 15 years' time, it might be able to make a really substantial difference. And yeah, I'm just not sure. I feel like we have to start putting some restrictions on open sourcing now, basically in anticipation of that.
Suleyman concluded the interview with a final comment on AI alignment:
This is a super critical issue. We need 10x more people focused on misalignment. In general, I'm a bit sensitive to the idea of deception because I think it's in itself a kind of anthropomorphism, but that's a technicality. In general, I think that absolutely the fundamental questions of misalignment, and in general AGI safety, and the 10-year risks, and the 20-year risks couldn't be more important.
The podcast is available at 80000hours.org, along with a full transcript of the interview. Or you can watch the video below.
Do you agree with Mustafa Suleyman's predictions about the exponential growth of AI models? How concerned are you about the ethical implications of rapidly advancing AI technology, and what steps do you think should be taken to mitigate these risks? What are your thoughts on open sourcing AI models? Let us know in the comments below!