14th November 2023 NVIDIA announces H200 Tensor Core GPU The world's most valuable chip maker has announced a next-generation processor for AI and high-performance computing workloads, due for launch in mid-2024. A new exascale supercomputer, designed specifically for large AI models, is also planned.
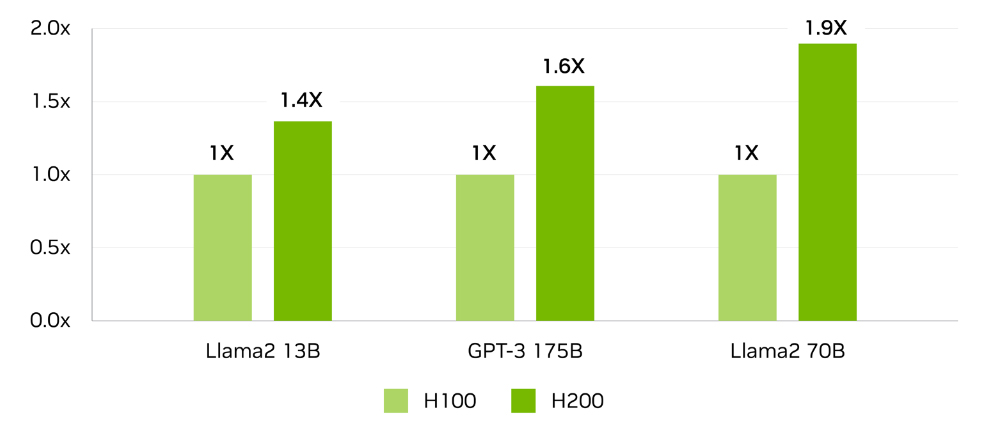
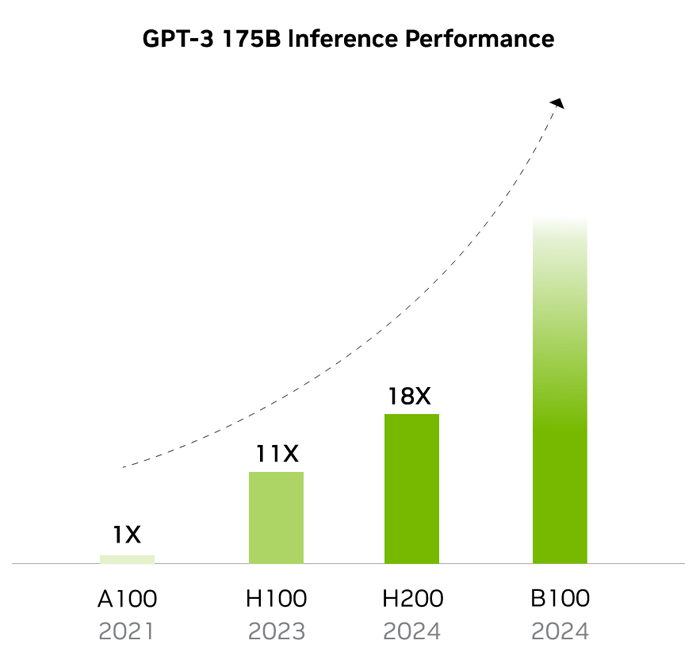
In recent years, California-based NVIDIA Corporation has played a major role in the progress of artificial intelligence (AI), as well as high-performance computing (HPC) more generally, with its hardware being central to astonishing leaps in algorithmic capability. In May 2020, the company debuted its A100, which set a new standard for graphics processing units (GPUs). GPUs are devices commonly used for applications with heavy computational demand, such as video production or gaming, but their massively parallel calculations make them ideal for AI workloads too. Built on "Ampere" architecture, the A100 featured 54 billion transistors based on a 7 nanometre (nm) process. A successor to the A100, called the H100, followed in September 2022. This had new "Hopper" architecture and used a 5 nanometre (nm) process, with a higher transistor count of 80 billion, six times the speed, double the memory and 3.5 times the energy efficiency of the A100. An even more capable variant known as the H100 NVL followed in March 2023. Now, NVIDA has announced its most powerful GPU to date: the H200. This will be the first GPU to use HBM3e, a cutting-edge module with 141 gigabytes (GB) of high-speed memory at 4.8 terabytes per second (TB/s). That is nearly double the capacity and provides 40% more bandwidth than last year's H100. In terms of large language model (LLM) inference performance, the H200 can provide a substantial speed boost. GPT-3, for example, which has a model size of 175 billion parameters, runs 1.6 times faster, while a 70 billion parameter version of Meta's Llama2 runs nearly twice as fast.
The H200 is also more eco-friendly than its predecessor, with 50% lower energy requirements. This is now a highly important consideration, given the explosive growth of GPUs and the resulting increase in electricity demands. Recent research has suggested that on current trends, AI used in data centres will consume as much electricity as a country the size of the Netherlands or Sweden by 2027. The H200 will be available in NVIDIA HGX H200 server boards, with options for both four- and eight-way configurations. If these modules are combined into an eight-way GPU system, the H200 will provide 32 petaFLOPS of deep learning compute at FP8 precision (smaller chunks of data that result in faster computations) and over 1.1TB of aggregate high-bandwidth memory. "To create intelligence with generative AI and HPC applications, vast amounts of data must be efficiently processed at high speed using large, fast GPU memory," said Ian Buck, Vice President of Hyperscale and HPC at NVIDIA. "With NVIDIA H200, the industry's leading end-to-end AI supercomputing platform just got faster to solve some of the world's most important challenges." H200-powered systems are expected to begin shipping in Q2 2024. Amazon Web Services, Google Cloud, Microsoft Azure, and Oracle Cloud Infrastructure will be among the first cloud service providers to deploy its capabilities. While impressive, the H200 is a mere taster for what is expected to follow later in 2024. An even more powerful GPU known as the B100 is also in development. Details of this system, the first to use a new "Blackwell" architecture, should be revealed in the coming months. Rumours indicate it will be a multi-chip module (MCM) device to improve scaling, made using Taiwan Semiconductor Manufacturing Company's (TSMC's) 3 nm process.
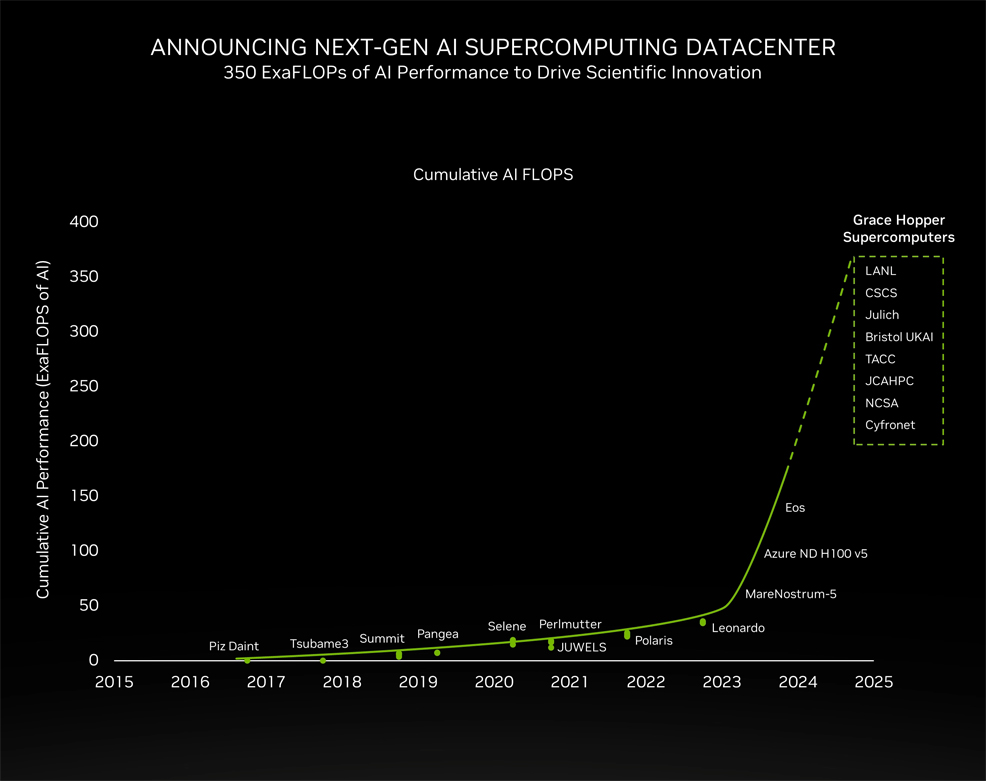
In addition to its H200 processor, NVIDIA announced plans for a new supercomputer, called JUPITER. This will be housed at the Forschungszentrum Jülich facility in western Germany and is being built in collaboration with several European companies – ParTec, Eviden and SiPearl. It will consist of 24,000 GH200 Superchips, providing a combined total of 1 exaFLOP for HPC applications and a massive 93 exaFLOPS for training AI. This is 45 times more than Jülich's previous system. NVIDIA revealed the GH200 chip, designed specifically for large-scale AI models, earlier this year at the COMPUTEX conference. According to NVIDIA's statement, the JUPITER system will "accelerate the creation of foundational AI models in climate and weather research, material science, drug discovery, industrial engineering and quantum computing" while consuming only 18.2 megawatts of power (relatively low for a supercomputer of this scale). "The JUPITER supercomputer powered by NVIDIA GH200 and using our advanced AI software will deliver exascale AI and HPC performance to tackle the greatest scientific challenges of our time," said Buck. "Our work with Jülich, Eviden and ParTec on this groundbreaking system will usher in a new era of AI supercomputing to advance the frontiers of science and technology." Installation of JUPITER at Jülich is expected in 2024. This machine is one of several to use NVIDIA's Hopper architecture. As shown below, the cumulative total amount of AI compute based on NVIDIA GPUs has reached an inflection point, which is likely to exceed 350 exaFLOPs or more by the end of next year. Or put another way: 350,000,000,000,000,000,000 calculations per second.
Comments »
If you enjoyed this article, please consider sharing it:
|